- Definition of Machine Learning
- Application of Machine Learning
- Activation Function
- Supervised Learning
- Unsupervised Learning
- Exploratory Data Analysis
- Simple Linear Regression
- Multiple Linear Regression
- Univariate Logistic Regression
- Multivariate Logistic Regression
- Introduction to Naive Bayes
- Naive Bayes for Categorical Data
- Naive Bayes for Text Classification
- Support Vector Machines
- Introduction to Decision Trees
- Introduction to Clustering
- K Mean Clustering
- K Mode Clustering
- DB Scan Clustering
- Pricipal Component Analysis
Machine Learning
Supervised Learning
Unsupervised Learning
Definition of Machine Learning
Machine learning is a subfield of artificial intelligence that focuses on the development of algorithms and models that enable computers to learn from data and make predictions or decisions without being explicitly programmed. It involves the study of statistical and computational techniques that allow machines to improve their performance on a specific task through experience or exposure to data.
Machine learning models can be classified into the following three types based on the task performed and the nature of the output:
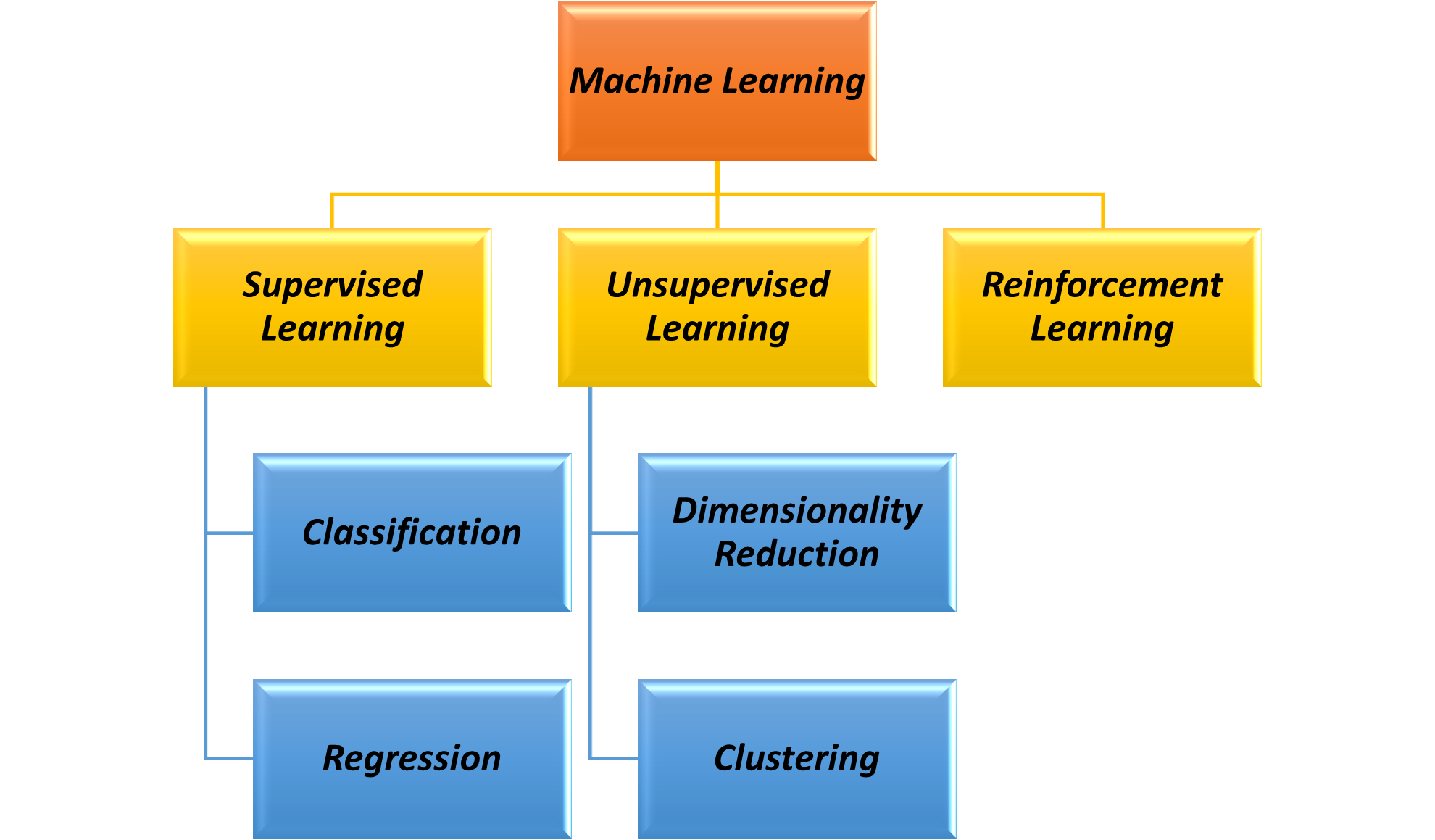
- Supervised Learning Algorithms: These algorithms learn from labeled training data, where each data point is associated with a known output or target value. They aim to learn the underlying patterns in the data to make predictions or classify new, unseen data.
- Unsupervised Learning Algorithms: Unsupervised learning algorithms deal with unlabeled data, where the goal is to discover patterns, structures, or relationships within the data. These algorithms can be used for clustering similar data points, dimensionality reduction, and anomaly detection. Popular algorithms in this category include k-means clustering, hierarchical clustering, principal component analysis (PCA), and generative models like Gaussian Mixture Models (GMM) and autoencoders.
- Reinforcement learning: Reinforcement learning is a way for computers to learn by trying things out and getting feedback. Just like how we learn from experience, a computer "agent" interacts with an environment and takes actions. When it does something good, it gets rewarded, and when it does something bad, it gets punished.
Supervised classification and supervised regression are two fundamental tasks in supervised machine learning. Both tasks involve training a model on labeled data, where the input data is associated with corresponding output labels or target values.
Supervised classification is a task in which a model learns to classify input data into predefined categories or classes. The goal is to build a model that can accurately assign new, unseen instances to the correct class based on the patterns and relationships learned from the labeled training data. For example, a model trained on a dataset of images with labeled categories (e.g., "cat" or "dog") can be used to classify new images into these categories.
In supervised classification, the output labels are discrete and represent distinct categories. The model learns from the features or attributes of the input data and their corresponding labels. The training process involves finding patterns, decision boundaries, or rules that differentiate the classes. Various algorithms, such as decision trees, support vector machines, and neural networks, can be used for supervised classification.
Supervised regression on the other hand, is a task where the model learns to predict a continuous numerical value or a set of values as output based on the input data. It aims to build a model that can accurately estimate or approximate the relationship between the input features and the target variable. For example, a regression model can predict the price of a house based on features such as its size, location, and number of rooms.
In Supervised regression he target variable is continuous, and the model learns a mapping from the input features to the target values. The training process involves finding the best-fitting function or equation that minimizes the difference between the predicted values and the actual target values in the training data. Regression algorithms, such as linear regression, polynomial regression, support vector regression, and neural networks, are commonly used for supervised regression tasks.
Note In both supervised classification and regression, the availability of labeled data is essential for training the models. The models generalize from the training data to make predictions on unseen or future data based on the learned patterns or relationships.